Я удивляюсь с этого синешапочника Эли. Видимо, он тоже вернулся из отпуска - жжет не по-детски. Выложил плагин PingCrawl для вордпресса, который пингует всё на свете.
При любом создании/изменении поста находит все тэги и делает для КАЖДОГО тэга так:
1. В гугл блого серче ищет 35 блогов.
2. С каждым найденным блогом делает так:
3. Проверяет, есть ли мета-тэг с адресом для пингбэка
4. Проверяет, есть в исходнике страницы адрес для трэкбэка
5. Если есть - сохраняет адрес пингбэка.
6. Если нет - пропускает блог - логично :)
7. Добавляет 5 годных для пинга линков в текущий пост.
8. Выбирает обратно из памяти урлы и отправляет пингбэки.
9. Гарантия пинга совсем не 100%, а примерно 80%.
Примечания.
1. Плагин создает две дополнительные таблицы в базе данных
2. Плагин случайным образом, примерно один раз на 13 линков, вставляет линк на скрипт сайта Эли. Кто знает ПХП - легко занулит. Я не буду.
3. Здается мне, что на ПХП 4 это не заработает патамушта плагин полностью сделан на объектной модели и требует Simple XML. УПС! Тут ведутся попытки сделать порт на ПХП 4.
4. Ресурсов жрет немеряно. 41 ХТТП запрос на каждый тэг в посте. Сдается мне, что на виртуальном хостинге погонят нас в шею с таким плагином или он по таймауту будет отваливаться.
5. Использует file_get_contents, который может быть выключен на виртуальном хостинге.
6. А код у них сука красивый :)
Пока я только думал, как бы это придумать с пингбэками и трэкбэками, Эли уже код готовый выложил. Респекты. Блин, забодался писать, работать некогда :( Завтра ничего писать не буду! Пока.
Прочитать полностью...
7 авг. 2008 г.
Эли спалил тему - опен сорс плагин для вордпресса, который оставляет пингбэки и/или трэкбэки по серпу гуглблогосерча.
6 июл. 2008 г.
Организация "блогоскопища" (с) (tm) 2008 F17 :) Деталь три.
Выдалось немного времени, настроил в блогоскопище перенаправление запросов в нужные каталоги.
Вот что получилось в .htaccess:
[IfModule mod_rewrite.c]
RewriteEngine On
# запросы с www отправляются на основной домен без www
RewriteCond %{HTTP_HOST} ^www\.domain\.com [NC]
RewriteRule ^(.*) http://domain.com/$1 [R=301,L]
# запросы к субдоменам с www отправляются на субдомен без www
RewriteCond %{HTTP_HOST} ^www\.([a-z0-9_-]+)\.domain\.com [NC]
RewriteRule ^(.*) http://%1.domain.com/$1 [R=301,L]
# картинки для субдоменов хранятся в каталоге subdomains/имя_субдомена/template/
# если убрать "%1/" ,то картинки всех субдоменов можно свалить в одну кучу subdomains/template/
RewriteCond %{HTTP_HOST} ^(.*)\.domain\.com [NC]
RewriteRule ([a-z0-9_-]+)\.(gif|jpg|jpeg|ico|css|png|js)$ subdomains/%1/template/$1.$2
# все запросы к несуществующим файлам приходят к index.php, который решает, что делать дальше
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule .+ ./index.php [L]
[/IfModule]
Совершенно другой вариант блогоскопища создает в прямом эфире http://blogclient.ru/.
Его вариант интересен тем, что он практически опенсорс. Блог тоже хороший.
Прочитать полностью...
4 июн. 2008 г.
Палю тему 19. Криворукие жулики в receivelinks
Для тех, кто работает в ресивлинсе (с реф) по аптекам, палю криворукого вебмастера:
http://www.theharleystreetpractice.com/wp/archives/
http://www.natural-remedies-clinic.co.uk/directory/
Снаружи линк выглядит нормально, а внутри дерьмо ( [ ] - это угловая скобка, соответсвенно левая и правая.)
[a href="http://greentea%3C/li%3E%3Cbr%3E%3Cbr%3E%3Cli%3EМойДомен.com/"]тут мой киворд[/a]
[p class="verd7b" align="center"]
juice.html" class="ads">Nakkesleng[br][br] [a href="http://www.olavogelse.com/noni%3Cbr%3E%3Cbr%3EМойДомен.com/" class="ads"]тут мой киворд[/a][/p]
Он не со зла. у него кривой вордпресс стоит. Я уже забодался его линки удалать, сначала думал может временный глюк - у кого не бывает. Проверьте и вносите в свой бан-лист на ресивлинксе.
Вот ещё один умник
http://www.gynecomastiaonline.com/topic/male-breast
[!--
[a href="чужое"]чужой киворд[/a] - [a href="чужое"]чужой киворд[/a] - [a href="чужое"]чужой киворд[/a] - [a href="чужое"]чужой киворд[/a] - [a href="моё"]мой киворд[/a]--]
Всё в комментах! Или гугл индексирует линки из комментов HTML?
ЗЫ
Процент таких линков удручающе велик. Кнопка БАН там не зря прикручена.
Во имя спасения моего времени, сегодня мой ридер покидает хороший блог
http://maxsite.org/
Это лучший блог про вордпресс на русском языке. Сейчас автор пишет свою опенсорс систему управления контентом, вордпресс забросил. Теперь мне не интересно.
Прочитать полностью...
31 мая 2008 г.
Джобаксы прислали старые новости.
Сегодня пришло письмо от джобаксов-маркетхелсов (с реф), что они запустили пять новых сетевых оффера, но на самом деле они там уже неделю болтаются. Я даже успел их в свой план включить.
Проблемы с передачей ref id есть не только у меня.
Выловил из рефспама вот такой сайт про provillus:
http://www.usfreeads.com/734663-cls.html
Его ссылки тоже из файерфокса не ставят куку и не передают реф айди, а из ИЕ6 - всё нормально. Файервол включен. И я и он теряем продажи от покупателей, у которых айфреймы режет файервол.
Сегодня мой ридер покидает хороший сайт:
http://www.life.lviv.name/wp/
Автор даром, т.е. даром, выложил опенсорс скрипт мультифида на умакс, пиклик, кликвип и 3фн. Добавить новую ППС не сложно. Также он выложил скрипт для проверки работоспосбоности серверов и автоматического переключения ДНС на запасной сервер. Но сам блог ничего интересного не представляет. Спасибо огромное за скрипты.
Прочитать полностью...
15 апр. 2008 г.
Гугл изменил формат выдачи - 2
Начало читать тут Гугл изменил формат выдачи.
Как оказалось, точнее позже разберусь, как правильно тулить PHP код в посты этого "№:?%;!( блогспота - там куча лишних кавычек. А пока вот фотография регулярки для автодора генератора от Ноулейка.
(нажать для увеличения)
Принощу извинения за непрофессионализм, я не волшебник, я только учусь.
Прочитать полностью...
28 мар. 2008 г.
Гугл изменил формат выдачи
Гугл изменил формат выдачи, в связи с чем перестал работать замечательный динамический дорвей. Когда поменялся формат я не знаю, заметил только вчера.
Вот мой вариант исправления регулярного выражения в файле serp_update.php:
$str4="\<h2 class="r\">(([\r\n])*[\s]*)\<a href="\">]+)\>(.+)\<\/a\>(([\r\n])*[\s]*)\<\/h2\>(.*)\<td class="\">\<div class="std\">(.*)(([\r\n])*[\s]*)\<br\>";
preg_match_all("/$str4/Uis",$file,$matches);
for($i=0; $i < count($matches[5]); $i++)
{
$item[$i]="<a href=".$matches[3][$i].">".$matches[5][$i]."</a><br />".$matches[9][$i]."<br />";
}
Опен сорс! As is!
Еле опубликовал. Хорошо, что в ноутпаде++ есть кнопка "конвертивать НТМЛ сущности" :(
Прочитать полностью...
21 мар. 2008 г.
Поскольку блог Эли досят, captchasolverproxy.zip выложил на рапиду.
Поскольку блог Эли досят, captchasolverproxy.zip, про который я писал ранее, выложил на рапиду. Ссылка под катом:
http://rapidshare.de/files/38886485/captchasolverproxy.zip.html
Прочитать полностью...
20 мар. 2008 г.
Досят блог Эли, видимо за ломалки капчей для форума PHPBB2
Не успели все порадоваться опенсорс ломалке капчей для форума PHPBB2, а уже досят блог Эли. This is a fantastic guest post by Harry over at DarkSEO Programming. His blog has some AWESOME code examples and tutorials along with an even deeper explanation of this post so definitely check it out and subscribe so he’ll continue blogging. This post is a practical explanation of how to crack phpBB2 easily. You need to know some basic programming but 90% of the code is written for you in free software. Programs you Need C++/Visual C++ express edition - On Linux everything should compile simply. On windows everything should compile simply, but it doesn’t always (normally?). Anyway the best tool I found to compile on windows is Visual C++ express edition. Download GOCR - this program takes care of the character recognition. Also splits the characters up for us ImageMagick - this comes with Linux. ImageMagick lets us edit images very easily from C++, php etc. Install this with the development headers and libraries. Download from here A (modified) phpbb2 install - phpBB2 will lock you out after a number of registration attempts so we need to change a line in it for testing purposes. After you have it all working you should have a good success rate and it will be unlikely to lock you out. Find this section of code: (it’s in includes/usercp_register.php) Make it this: if ($row = $db->sql_fetchrow($result)) Possibly a version of php and maybe apache web server on your desktop PC. I used php to automate the downloading of the captcha because it’s very good at interpreting strings and downloading static web pages. Getting C++ Working First The problem on windows is there is a vast number of C++ compilers, and they all need setting up differently. However I wrote the programs in C++ because it seemed the easiest language to quickly edit images with ImageMagick. I wanted to use ImageMagick because it allows us to apply a lot of effects to the image if we need to remove different types of backgrounds from the captcha. Once you’ve installed Visual C++ 2008 express (not C#, I honestly don’t know if C# will work) you need to create a Win32 Application. In the project properties set the include path to something like (depending on your imagemagick installation) C:\Program Files\ImageMagick-6.3.7-Q16\include and the library path to C:\Program Files\ImageMagick-6.3.7-Q16\lib. Then add these to your additional library dependencies CORE_RL_magick_.lib CORE_RL_Magick++_.lib CORE_RL_wand_.lib. You can now begin typing the programs below. If that all sounds complicated don’t worry about it. This post covers the theory of cracking phpBB2 as well. I just try to include as much code as possible so that you can see it in action. As long as you understand the theory you can code this in php, perl, C or any other language. I’ve compiled a working program at the bottom of this post so you don’t need to get it all working straight away to play with things. Getting started Ok this is a phpBB2 captcha: It won’t immediately be interpreted by GOCR because GOCR can’t work out where the letters start and end. Here’s the weakness though. The background is lighter than the text so we can exclude it by getting rid of the lighter colors. With ImageMagick we can do this in a few lines of C++. Type the program below and compile/run it and it will remove the background. I’ll explain it below. int main( int /*argc*/, char ** argv) // Initialize ImageMagick install location for Windows // load in the unedited image // remove noise // save image return(1); All this does is loads in the image, and then calls the function threshold attached to the image. Threshold filters out any pixels below a certain darkness. On linux you have to save the image as a .png however on windows GOCR will only read .pnm files so on linux we have to put the line instead: Ok that’s one part sorted. Problem 2. We now have another image that GOCR won’t be able to tell where letters start and end. It’s too grainy. What we notice though is that each unjoined dot in a letter that is surrounded by dots 3 pixels away should probably be connected together. So I add a piece of code onto the above program that looks 3 pixels to the right and 3 pixels below. If it finds any black dots it fills in the gaps. We now have chunky letters. GOCR can now identify where each letter starts and ends void fill_holes(PixelPacket * pixels, int cur_pixel, int size_x, int size_y) ///////////// pixels to right ///////////////////// // first of all are we a black pixel, no point if we are not if(*(pixels+index)==Color("black")) ///////////// pixels to bottom ///////////////////// if(*(pixels+cur_pixel)==Color("black")) if(*(pixels+index)==Color("black")) } int main( int /*argc*/, char ** argv) // Initialize ImageMagick install location for Windows // load in the unedited image // remove noise ///////////////////////////////////////////////////////////////////////////////////////////////////// // define the view area that will be accessed via the image pixel cache // return a pointer to the pixels of the defined pixel cache // go through each pixel and if it is black and has black neighbors fill in the gaps // now that the operations on my_pixel_cache have been finalized // save image return(1); I admit this looks complicated on first view. However you definitely don’t have to do this in C++ though if you can find an easier way to perform the same task. All it does is remove the background and join close dots together. I’ve given the C++ source code because that’s what was easier for me, however the syntax can be quite confusing if you’re new to C++. Especially the code that accesses blocks of memory to edit the pixels. This is more a study of how to crack the captcha, but in case you want to code it in another language here’s the general idea of the algorithm that fills in the holes in the letters: 1. Go through each pixel in the picture. Remember where we are in a variable called cur_pixel NOTE: Just make sure you don’t let any variables go over the edge of the image otherwise you might crash your program. I used the same algorithm but modified it slightly so that it also looked 3 pixels below, however the steps were exactly the same. Training GOCR The font we’re left with is not recognized natively by GOCR so we have to train it. It’s not recognized partly because it’s a bit jagged. Assuming our cleaned up picture is called convert.pnm and our training data is going to be stored in a directory call data/ we’d type this. gocr -p ./data/ -m 256 -m 130 convert.pnm Just make sure the directory data/ exists (and is empty). I should point out that you need to open up a command prompt to do this from. It doesn’t have nice windows. Which is good because it makes it easier to integrate into php at a later date. Any letters it doesn’t recognize it will ask you what they are. Just make sure you type the right answer. -m 256 means use a user defined database for character recognition. -m 130 means learn new letters. You can find my data/ directory in the zip at the end of this post. It just saves you the time of going through checking each letter and makes it all work instantly. Speeding it up Downloading, converting, and training for each phpbb2 captcha takes a little while. It can be sped up with a simple bit of php code but I don’t want to make this post much longer. You’ll find my script at the end in my code package. The php code runs from the command prompt though by typing “php filename.php”. It’s sort of conceptual in the sense that it works, but it’s not perfect. Done Ok once GOCR starts getting 90% of the letters right we can reduce the required accuracy so that it guesses the letters it doesn’t know. Below I’ve reduced the accuracy requirement to 25% using -a 25. Otherwise GOCR prints the default underscore character even for slightly different looking characters that have already been entered. -m 2 means don’t use the default letter database. I probably could have used this earlier but didn’t. Ah well, it doesn’t do a whole lot. gocr -p ./data/ -m 256 -m 2 -a 25 convert.pnm We can get the output of gocr in php using: echo exec(”/full/path/gocr -p ./data/ -m 256 -m 2 -a 25 convert.pnm”); Alternatives In some instances you may not have access to GOCR or you don’t want to use it. Although it should be usable if you have access to a dedicated server. In this case I would separate the letters out manually and resize them all to the same size. I would then put them through a php neural network which can be downloaded from here FANN download It would take a bit of work but it should hopefully be as good as using GOCR. I don’t know how well each one reacts to letters which are rotated though. Neural networks simply memorize patterns. I haven’t checked the inner workings of GOCR. It looks complicated. My code All the code can be found here to crack phpBB2 captcha. In conclusion to this tutorial it’s a nightmare trying to port over all my code from linux to windows unless it’s written in Java It’s worth stating that phpbb2 was easy to crack because the letters didn’t touch or overlap. If they had touched or overlapped it would probably have been very hard to crack. I plan to look at that line and square captcha that comes with phpBB3 over on my site and document how secure it is. Thanks for the awesome guest post Harry.
Выкладываю из ридера, может кому пригодится. Сам файл с исходниками вышлю по запросу в комментах. Блин, пока найти не могу, куда я его засунул :( Кто понимает С++ и английский - без труда напишет заново. Сорри. ! UPDATE ! Выложил для скачивания исходники ломалки капчей.
Итак гостевая статья Гарри на блоге Эли, картинки не существенные, там просто "проявляется" текст из капчи:
![]() . It’s pretty easy to do that manually but hey. Download
. It’s pretty easy to do that manually but hey. Download if ($row = $db->sql_fetchrow($result))
{
if ($row['attempts'] > 3)
{
message_die(GENERAL_MESSAGE, $lang['Too_many_registers']);
}
}
$db->sql_freeresult($result);
{
//if ($row[’attempts’] > 3)
//{
// message_die(GENERAL_MESSAGE, $lang[’Too_many_registers’]);
//}
}
$db->sql_freeresult($result);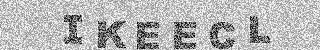
using namespace Magick;
{
InitializeMagick(*argv);
Image phpBB("test.png");
phpBB.threshold(34000);
phpBB.write("convert.pnm");
}
// save image
phpBB.write("convert.png");
The background removed.![]() . We’re pretty much nearly done.
. We’re pretty much nearly done.
using namespace Magick;
{
int max_pixel, found;
found = 0;
max_pixel = cur_pixel+3; // the furthest we want to search
// set a limit so that we can't go over the end of the picture and crash
if(max_pixel>=size_x*size_y)
max_pixel = size_x*size_y-1;
if(*(pixels+cur_pixel)==Color("black"))
{
// start searching from the right backwards
for(int index=max_pixel; index>cur_pixel; index--)
{
// should we be coloring?
if(found)
*(pixels+index)=Color("black");
found=1;
}
}
found = 0;
max_pixel = cur_pixel+(size_x*3);
if(max_pixel>=size_x*size_y)
max_pixel = size_x*size_y-1;
{
for(int index=max_pixel; index>cur_pixel; index-=size_x)
{
// should we be coloring?
if(found)
*(pixels+index)=Color("black");
found=1;
}
}
{
InitializeMagick(*argv);
Image phpBB("test.png");
phpBB.threshold(34000);
// Beef up "holey" parts
/////////////////////////////////////////////////////////////////////////////////////////////////////
phpBB.modifyImage(); // Ensure that there is only one reference to
// underlying image; if this is not done, then the
// image pixels *may* remain unmodified. [???]
Pixels my_pixel_cache(phpBB); // allocate an image pixel cache associated with my_image
PixelPacket* pixels; // 'pixels' is a pointer to a PixelPacket array
// literally below we are selecting the entire picture
int start_x = 0;
int start_y = 0;
int size_x = phpBB.columns();
int size_y = phpBB.rows();
pixels = my_pixel_cache.get(start_x, start_y, size_x, size_y);
// this calls the function fill_holes from above
for(int index=0; index < size_x*size_y; index++)
fill_holes(pixels, index, size_x, size_y);
// ensure that the pixel cache is transferred back to my_image
my_pixel_cache.sync();
phpBB.write("convert.pnm");
}
2. Start three pixels to the right of cur_pixel. If it’s black color the pixels between this position and cur_pixel black.
3. Work backwards one by one until we reach cur_pixel again. If any pixels we land on are black then color the space in between them and cur_pixel black.
4. Go back to step 1 until we’ve been through every pixel in the picture
![]() . If only Java was small and quick as well.
. If only Java was small and quick as well.
Прочитать полностью...

